在线查询系统性能优化

背景
在最近的一个项目是一个后台管理工具,WEB端需要根据后端录入的数据,显示一个庞大的表格。主要的几点需求如下:
- 每条记录包含多个字段,都需要显示在WEB端界面上
- 其中有些字段并不能通过数据库查询直接得出,需要另外计算得出
- 支持设置过滤条件和按字段排序
- 需求变化很快,字段可能随时调整
对此,后端为了整体解决,会把查询得到的所有记录都合并到一起作计算,得到包含所有字段的完整数据。有了完整的数据,之后的过滤和排序就相对容易实现了。
问题
这种设计在项目初期的确对快速变化的需求表现出了良好的应变能力。然而随着数据量的增加,该方案也出现了明显的性能问题,经分析发现主要的问题出在以下几个方面:
- 随着数据量增加,对所有记录做计算越来越耗时
- 因为数据量的关系,从数据库服务器取出记录的过程本身也很耗时
解决这两个问题的根本都是是减少数据量。很明显,不符合过滤条件的记录没有必要传输到后端服务器上,也没有必要做字段计算。如果可以提前得到甚至缩小符合过滤条件的记录ID,可以大大加速整个过程。
索引表
针对前端特殊的展示需求(一张大表格),一个直观的解决方案是扁平化所有的数据。为此我们新建了一张索引表SearchTable,将每条记录的相应字段预先计算并填入。数据表结构如下:
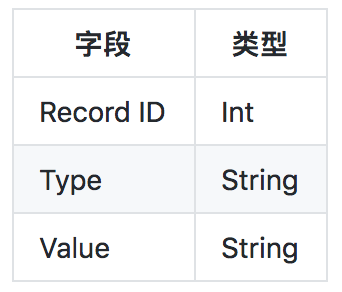
索引表中的每一行对应一条记录的字段及其取值,其中type标识了该行字段名称,value则是对应的值。
这样过滤条件可以转化为类似如下的查询语句,无需任何计算就可以直接得到满足条件记录的ID:
SELECT record_id FROM SearchTable WHERE
record_id in (SELECT record_id FROM SearchTable WHERE type='typeA' AND value in (valueA1, valueA2, ...))
AND
record_id in (SELECT record_id FROM SearchTable WHERE type='typeB' AND value in (valueB1, valueB2, ...))
AND
...
索引表初始化
索引表上线前需要对当前所有记录做初始化,另外如果上线后发生不一致的问题,也需要一个重建过程。因此重建是一个重要功能,需要做成一个相对独立的模块以供将来方便调用。重建过程即是对指定记录,重新计算其所有字段的值填入索引表。
索引表更新
任何对记录的删改,都必须同时更新索引表,否则会造成之后的查询结果不一致。需要注意的是索引表更新必须跟记录更新在同一个数据库事务中进行,保证数据一致性。
索引表本质上是用空间(冗余数据)换时间(查询速度)。
分页
用户不可能一次性查看所有记录,分页是前端普遍采用的优化策略。但使用索引表之前,分页起到的作用仅仅是减少了WEB服务器到浏览器的数据传输,数据库到WEB服务器,以及WEB服务器本身的数据处理量完全没有减少。
引入索引表后,直接利用索引表进行排序分页操作成为了可能。一旦最终分页结果可以通过索引表确定,数据库到WEB服务器和WEB服务器本身的数据量也可以享受到分页的优化效果。
利用索引表做分页有两个条件:
- 所有过滤条件都在索引表中
- 分页排序的字段也在索引表中
如下是一个按照创建时间排序并按每页300条记录分页的例子(注意排序时候cast函数的使用):
SELECT record_id FROM SearchTable WHERE
record_id in (SELECT record_id FROM SearchTable WHERE type='typeA' AND value in (valueA1, valueA2, ...))
AND
record_id in (SELECT record_id FROM SearchTable WHERE type='typeB' AND value in (valueB1, valueB2, ...))
AND
...
AND
type='time_created'
ORDER BY cast(value as unsigned) DESC
LIMIT 300
分步迁移
性能优化从来都是一项复杂、长期的工程,尤其在大型系统中更为如此。因此优化的分步推进有很大的必要性,既可以让系统不断享受到优化的红利,也可以保证系统的稳定性,不会因为大规模的改动引入过高的风险。索引表也恰恰满足了我们这方面的需求。
对此,我们改造了原有的代码,使其支持在给定记录ID范围内进行处理。
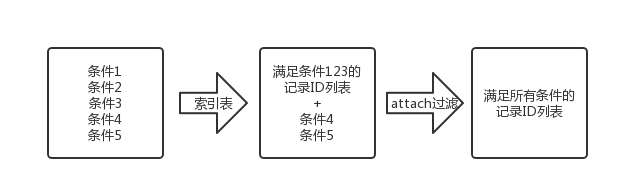
这样,不用等到所有字段迁移完索引表便可以上线工作。通过已经迁移的字段可以预先查询到一个相对较大的记录范围,再交给原来的过滤程序进行处理。也能起到一定的优化效果,也给优化争取了宝贵的时间。性能优化是一个大工程,从来不可能一蹴而就。
分布迁移的好处还有:
- 可以分步到线上检验实际效果,及时修复暴露出的问题
- 可以根据效果及时调整优化方案
缓存的合理使用
最后说一下数据库系统中缓存的使用。缓存作为一个传统优化技术,还是有其不可替代的作用。
在本项目中,索引表的引入虽然很大程度上解决了目前碰到的性能问题,但并不能解决所有问题,特别是一些小粒度上的优化,还得依赖传统的缓存技术。缓存的合理使用可以很大程度上缓解数据库的访问压力。
缓存的使用原则一般遵循80/20原则:如果80%的访问集中在20%的数据上,这些数据很可能非常适合做缓存优化。缓存的命中率是一个很重要的指标,如果命中率太低,说明缓存效果很差,可能还不如不设置缓存。
一个简单的例子是从索引表得到记录ID后,需要根据ID取出对应的记录。这时候缓存就派上用场了,如果事先将记录数据缓存在内存中,那么可以很大程度上减少对数据库的访问。
可见缓存和数据库的合理搭配使用,才是后端性能优化的关键。