Glow Cache 构架

作为一家大数据公司,Glow每天都会收到海量的数据。这些数据的快速存取,是必须面对的一个问题。Cache,则是众多解决方案中,最实用的一个。笔者将给大家介绍一下Glow的Cache框架,希望能对广大创业团队有所帮助。
什么是Cache
Wiki上说:a cache is a component that stores data so future requests for that data can be served faster
在绝大多数服务器框架中,就是用内存代替数据库,以达到提高速度的目的。
传统的Cache有两种结构,write-through和write-back。
- write-through:一个写操作(write)同步更新cache和backend storage
- write-back:一个写操作(write)只更新cache,当再有变化发生时,写回backend storage
显然,write-back更高效,但更复杂。作为创业公司,我们首选write-through:
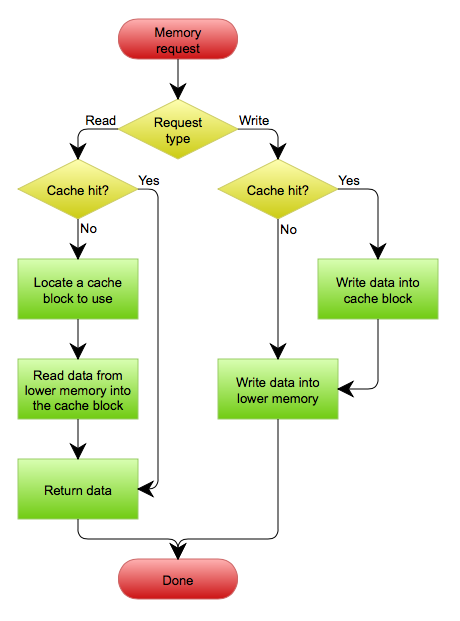
Cache hit rate
在cache使用中,cache hit rate(命中率)是一个衡量cache的重要指标。
你不可能无限制地把所有数据都写入cache中,cache system总会把一些数据丢弃。当一个“读”操作访问了不在cache中的数据,会产生一次backend storage读,以及一次cache“写”(写回cache),我们称之为cache miss。显然,一个cache miss会比直接访问backend storage有更大的开销。因此一个成熟的cache系统,应该极大地降低cache miss,保持cache hit在90%,甚至更高。
Glow Cache 概括
不管是write-through还是write-back,任何一次“写”操作,都会更新cache。而cache的目的,是提高“读”操作的速度。细心的读者或许会发现,这其中有一些逻辑上的问题:如果“写”完的数据,不再被“读”,不是白写了?
的确。如果“写”操作和“读”操作相对平衡,那这样的设计将会有比较好的效果。因为cache system会定期把数据丢弃。如果“写”进cache的数据,有90%在被cache丢弃前就被“读”过,那么hit rate就有90%。但实际生产环境中,我们发现,“写”操作和“读”操作并不平衡:
- 在用户记录健康信息的时候,“读”操作远远低于“写”操作,而“写”进cache的数据,一部分会被马上“读”到,另一部分不会被马上“读”到。
- 而在用户浏览论坛的时候,“读”操作则远远高于“写”操作,并且“读”操作请求的数据,大部分都不是刚被“写”过的。
为了达到90% cache hit rate,提高cache的容量,是一个简单粗暴的方式。这样,“写”进cache的数据,会存留更多的时间,随时准备被“读”。但随着数据量越来越大,经济成本会越来越高,即便一个创业团队能负担的起,也非常不划算——性价比太低。
作为一个服务器构架师,创业公司的程序猿,应该采用最合适的技术框架,即解决问题又节约成本。于是,Glow的cache,是一种结合了write-through和write-on-read的框架。
Glow Cache:当“写”操作发生时,使用cache的程序员,有能力决定写回cache,或删掉cache,甚至任何其他操作:
- 写回cache,就是write-through。
- 删掉cache,当下次“读”操作来时,再从backend storage里取。即所谓的write-on-read
- 其他任何操作
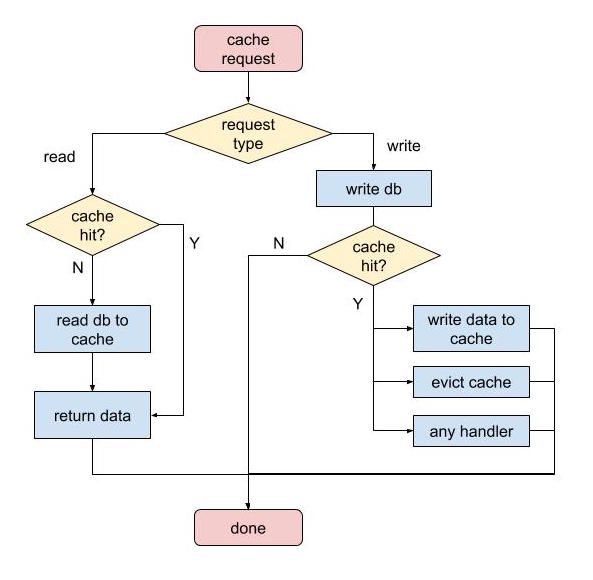
在实际生产环境中,在用户记录健康信息的时候,会被马上“读”到的数据,我们采用write-through,比如DailyDataCache,后面会有例子;另一部分不会被马上“读”到的数据,我们采用write-on-read。
Glow Cache 实现
Glow Cache 使用Redis作为内存存储解决方案。
Glow有复数台服务器处理产品的业务逻辑,每一台服务器都有复数个service,有些配有cache。
让我们通过一个具体的例子UserCache,来介绍Glow的Cache结构。
class UserCache(object):
@property
def handlers(self):
return {
UserCacheEvent.USER_REMOVED: self.evict,
UserCacheEvent.USER_UPDATED: self.evict,
}
def __init__(self, conn, dbpool, notif):
self.conn = conn
self.dbpool = dbpool
[notif.subscribe(event, self.handle_event) for event in self.handlers.keys()]
def handle_event(self, event_name, event_obj):
func = self.handlers.get(event_name)
func(event_name, event_obj)
def evict(self, event_name, event_obj):
self.conn.delete(event_obj.user_id)
class UserCacheEvent(object):
USER_REMOVED = 'USER_REMOVED'
USER_UPDATED = 'USER_UPDATED'
def __init__(self, user_id):
self.user_id = user_id
Cache instance
class UserCache(object):
def __init__(self, conn, dbpool, notif):
self.conn = conn
self.dbpool = dbpool
[notif.subscribe(event, self.handle_event) for event in self.handlers.keys()]
每一个cache的实例,都配备有:
- 有连到Redis服务器的链接:
conn,用于支持内存读写。任何“读写”cache的操作,都需要操作conn。e.g,self.conn.set(user_id, {...})。具体命令可以翻阅Redis的官方文档。 - 连接到数据库的dbpool,用于支持数据库读写。当cache miss发生的时候,需要从dbpool里取一个db connection,进而从数据库里取相应的数据。
- 一个Notification Center的实例:
notif。并且向notif注册(subscribe)所有用到的event。
Cache的更新
当“写”操作发生时,Cache需要做相应的更新。Glow的Cache structure在更新时,会做如下几件事:
(1) 首先,Cache在被实例化的时候,都向notif注册了一系列event。在UserCache在这个例子中,有两个event:USER_CREATED和USER_UPDATED。他们的响应方法都是evict
(2) 当User被更新时,构建一个UserCacheEvent的实例,并向notif publish这个event:
def update(self, dbc, user_id, values):
# 更新数据库
UserDBLogic(dbc).update(user_id, values)
# 更新cache
notif.publish(UserCacheEvent.USER_UPDATED, UserCacheEvent(user_id))
(3) Notification Center(notif)会依次调用每一个响应函数。UserCache.evict被响应,其中event_obj就是UserCacheEvent(user_id)这个实例,event_obj.user_id就能取到被更新的user_id。而做的事情,就是在Redis里删除这个user。
def evict(self, event_name, event_obj):
self.conn.delete(event_obj.user_id)
或许有人会问,Notification Center是每个进程一个,还是全局只有一个?
Glow拥有多台服务器,每台服务器都有多个service进程,每个进程都有自己的cache,自己的Notification Center。当某个进程接收了更新User的请求,publish了USER_UPDATED event,只有当前进程Notification Center会接收到这个event,并执行相应的操作。但Redis是全局唯一的。任何“读写”Redis的操作,都会影响同一份数据。所以,即便只有当前进程的Notification Center响应了event,因为最终会修改Redis里的数据,这样进程的cache再去读Redis的话,也会读到修改后的数据。
Cache的读
当“读”操作发生时,Cache应该做哪些事情?基本上,一个Cache应该实现以下方法:
- set(): a function to set a key with val into cache
- remove(): a function to remove a key
- get(): the interface function, to get value in cache or backend
- get_from_cache(): called by get(), try to get value from cache
- get_from_backend(): called by get(), get value from backend
其中,get()函数的实现如下:
def get(self, key):
try:
return self.get_from_cache(key)
except KeyMissingError:
v = self.get_from_backend(key)
self.set(v)
return v
逻辑本身并不复杂,相信懂code同学一眼就能看明白。但实际生产环境中,这样做有一个问题。一个很严重的问题,相信绝大部分同学都会遇到——进程安全。
Cache的进程安全
互联网大数据创业公司中,很少有一台服务器就能处理所有业务请求的例子,Glow也不例外。在任何分布式系统中,“数据”需要有一个唯一的源头,一般来说,数据库系统扮演了这个角色。但因为Cache的引入,Redis首先扮演了这个角色。不同之处在于,各种数据库(mysql, oracle等等)都发展了几十年,在并发响应,行锁,表锁,安全级别等等方面,都有很成熟的表现。而Redis,作为一个内存存储解决方案,“并发安全”并不是它的特长。
理论上来说,Cache的读和写,都应该上锁。
相信有服务器编程经验的同学,一定会对进程间上锁,取锁,释放锁,防止锁死(dead lock)等等,深恶痛绝。Glow作为一家创业公司,不可能做到尽善尽美。做90分的系统,适应99%以上的case。相信这也是大部分创业公司的选择。
具体到Glow cache的例子,我们有选择性的,适度的加锁。
在实际生产环境中,的确会遇到好几个进程处理同一个cache中的同一条记录。分析了很多情况之后,我们总结如下:
-
首先,要认识到,当多个进程读写cache时,Redis中存的值,并不等于各个进程cache的返回值。因为Redis是全局唯一的,而各个进程自己管理cache instance。
-
当数据库中有值,而cache.get()返回None的时候,是比较大的问题。因为,当业务代码发现一条记录不存在的时候,最多的操作是两类:insert,会抛
DuplicatedEntry;或直接抛异常(UserNotFoundException)。我们之后会通过例子分析。 -
当数据库中有值,而cache.get()返回一个旧值的时候,这并不是一个很严重的问题。因为,这种情况经常发生在进程A在“读”cache,进程B在“写”cache。无论进程A“读”到新值还是旧值,都是可以接受的。
-
当Redis中存的值,和数据库中的值不一致的时候,比较复杂。理论上,它很严重,要解决它必须上“读写”锁。但实际上,可以通过优化业务代码,尽量避免有多个进程更新同一条row,且更新的值不同。
-
复数个cache进程同时访问数据库,并更新Redis。如果
get_from_backend比较轻量,执行较快,那无非就是浪费一些机器资源。如果get_from_backend执行很慢,就需要仔细对待。例如,有一个cache专门存论坛中的关注者。假设,同一时间,有5个用户在论坛里关注了某个大V,就同时有5个进程要更新这个cache。大V有非常多的关注者,单次get_from_backend要执行5秒。当5个很大的query请求,同时访问数据库的同一张表时,数据库成了瓶颈,使得本来5秒的请求变得更慢,甚至20秒才能做完。另外,其他一些用户请求本来只要0.1秒,却因为数据库的拖累,响应时间变得很长。表现出来的现象,就是Glow所有的用户请求都很慢。事实上,完全可以只有一个进程执行get_from_backend,让其他进程进入等待,在得到get_from_backend结果之后,唤醒另外4个进程,从get_from_cache里取结果即可。
带锁的cache读
综上所述,结合Glow 业务逻辑的实际情况,我们只给cache加了一道锁:get_from_backend_with_lock。而且,每一个cache可以自己选择是否打开这个锁。
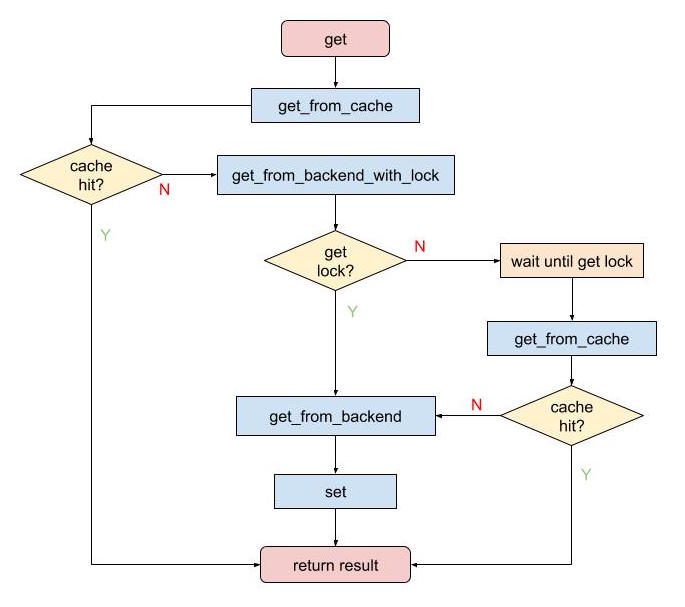
对于其他情况,我们可以通过调整业务代码,以减少冲突,又或是忽略不计。
自带锁:Redis的原子操作
前文提到,当数据库中有值,而cache.get()返回None的时候,由于Glow的业务逻辑会导致很多异常,我们要尽量避免。而且,当这种情况发生的时候,我们发现Redis的值,并没有和数据库不一致。那么,为什么正常的业务逻辑,会产生cache的读取错误呢?
我们先来看一下cache中get_from_cache的实现:
def get_from_cache(self, key):
if not self.conn.exists(key):
raise KeyMissingError(key)
else:
return self.conn.get(key)
如果你不是很精通服务器编程,可能看不出任何问题。但对于擅长服务器编程的同学来说,可能马上就注意到了:self.conn.exists(key)和self.conn.get(key)之间并没有上锁。在高并发的环境下,完全有可能被其他进程改变结果。实际生产环境中,的确如此。
进程1 进程2 进程3
| | |
| get_user |
| (redis key is set) |
get_user | |
cache.conn.exists? (Yes) | |
| | update_user
| | (redis key is removed)
cache.conn.get -> None | |
| | |
v v v
解决方案也很简单,直接使用conn.get的返回值判断是否存在,把get_from_cache变成原子操作:
def get_from_cache(self, key):
val = self.conn.get(key)
if val is None:
raise KeyMissingError(key)
return val
Glow cache的write-through
之前,我们都在介绍write-on-read。下面我通过另一个例子来给大家介绍Glow cache的write-through
class DailyDataCache(object):
@property
def handlers(self):
return {
DailyDataCacheEvent.DAILY_DATA_UPDATED: self.daily_data_updated,
DailyDataCacheEvent.DAILY_DATA_CLEARED: self.evict_sub
}
def daily_data_updated(self, event_name, event_obj):
# check cache before update
try:
self.hget_from_cache(event_obj.user_id, event_obj。date)
except KeyMissingError:
return
if event_obj.daily_data:
self.conn.hset(event_obj.user_id, event_obj.date, event_obj.daily_data)
else:
self.delete_subkey(event_obj.user_id, event_obj.date)
def evict_sub(self, event_name, event_obj):
self.delete_subkey(event_obj.user_id, event_obj.date)
class DailyDataCacheEvent(object):
DAILY_DATA_UPDATED = 'DAILY_DATA_UPDATED'
DAILY_DATA_CLEARED = 'DAILY_DATA_CLEARED'
def __init__(self, user_id, date, daily_data=None):
self.user_id = user_id
self.date = date
self.daily_data = daily_data
def upsert_daily_data(self, dbc, user_id, date, update_values):
with dbc_transaction_block(dbc):
result = UserDailyDataLogic(dbc).upsert(user_id, date, update_values)
notif.publish(DailyDataCacheEvent.DAILY_DATA_UPDATED,
DailyDataCacheEvent(user_id, date, result))
return result
在DailyDataCache中,有两个event:DAILY_DATA_UPDATED和DAILY_DATA_CLEARED。和UserCache不同,我们并不单纯地只采用evict响应(这样的话,就是write-on-read),而是在update的情况下,直接修改cache。
实际生产环境中,每一次的DailyData update,都会紧接着几次DailyData read。如果用evict处理,至少会多一次数据库读(get_from_backend),而这次读是没有必要的,因为upsert函数已经提供了必须数据。
细心的同学可能会发现,这么做也有一个隐含的问题:
- 当进程A和进程B同时更新一条DailyData的时候,可能会发生:A的数据先写进数据库,B的数据后写进数据库;但B的数据先写进cache,A的数据后写进cache。这样会发生数据库和cache不一致的问题。
这个进程安全问题,之前我们也提到了。Glow的解决方法是,尽量避免有A和B两个进程,写同一天的DailyData,并且数据不同。事实上,也没有这样的需求。如果哪一天,我们的业务逻辑会从产生这样的情况,那就需要对DailyDataCache.daily_data_updated加锁。
更进一步,在Glow cache的结构下,event的响应可以是任意一个函数。一个Cache的程序员可以利用这个函数,做任何事情,比如合并两个row,多次数据库查询,等等。这就给了程序员更大的自由度。
另外,如果cache中本身并没有这条数据,根据write-through的规则,我们不应该更新cache。所以增加了如下判断:
def daily_data_updated(self, event_name, event_obj):
# check cache before update
try:
self.hget_from_cache(event_obj.user_id, event_obj。date)
except KeyMissingError:
return
小结
今天,笔者给大家介绍了Glow cache的框架,这是一种结合了write-through和write-on-read,并且给予了程序员一定自由度的cache框架。
它并不完美,有一些并发安全的问题,甚至开放的自由度也会带来一些cache数据一致性问题。但它能解决Glow 99%以上的需求。一个脱离实际业务逻辑,大而全cache框架,不符合创业公司的实际情况。希望Glow的cache框架能为创业伙伴们带来一丝灵感,解决一些问题。也希望和广大程序猿一起讨论,进步。